Rootless kubernetes
Общее описание
Запуск Kubernetes в режиме rootless обеспечивает запуск Podов без системных root-привелегий в рамках user namespace системного пользователя u7s-admin. Работа в этом режиме практически не требует никаких модификаций, но обеспечивает повышенные уровень защищенности kubernetes, так как клиентские приложения даже при использовании уязвимостей не могут получить права пользователя root и нарушить работу узла.
Запуск kubernetes версии 1.26.3 и старше в режиме rootless обеспечивает пакет podsec-k8s версии 1.0.5 или выше.
podsec-k8s - Быстрый старт
Установка master-узла
Инициализация master-узла
Для запуска kubernetes в режиме rootless установите пакет podsec-k8s версии 1.0.5 или выше.
apt-get install podsec-k8s
Измените переменную PATH:
export PATH=/usr/libexec/podsec/u7s/bin/:$PATH
В каталоге /usr/libexec/podsec/u7s/bin/ находятся программы, обеспечивающие работы kubernetes
в rootless-режиме.
Для разворачивания master-узла запустите команду:
kubeadm init
По умолчанию уровень отладки устанавливается в
0. Если необходимо увеличить уровень отладки укажите перед подкомандойinitфлаг-v n. Гдеnпринимает значения от0до9-ти.
После:
- генерации сертификатов в каталоге
/etc/kubernetes/pki, - загрузки образов,
- генерации conf-файлов в каталоге
/etc/kubernetes/manifests/,/etc/kubernetes/manifests/etcd/ - запуска сервиса
kubeletиPod’ов системныхkubernetes-образов
инициализируется kubernet-кластер из одного узла.
По окончании скрипт выводит строки подключения master(Control Plane) и worker-узлов:
You can now join any number of control-plane nodes by copying certificate authorities and service account keys on each node and then running the following as root: kubeadm join xxx.xxx.xxx.xxx:6443 --token ... --discovery-token-ca-cert-hash sha256:.. --control-plane Then you can join any number of worker nodes by running the following on each as root: kubeadm join xxx.xxx.xxx.xxx:6443 --token ... --discovery-token-ca-cert-hash sha256:...
Запуск сетевого маршрутизатора для контейенеров kube-flannel
Для перевода узла в состояние Ready, запуска coredns Pod’ов запустите flannel.
На master-узле под пользоваталем root выполните команду:
# kubectl apply -f /etc/kubernetes/manifests/kube-flannel.yml Connected to the local host. Press ^] three times within 1s to exit session. [INFO] Entering RootlessKit namespaces: OK namespace/kube-flannel created clusterrole.rbac.authorization.k8s.io/flannel created clusterrolebinding.rbac.authorization.k8s.io/flannel created serviceaccount/flannel created configmap/kube-flannel-cfg created daemonset.apps/kube-flannel-ds created Connection to the local host terminated.
После завершения скрипта в течении минуты настраиваются сервисы мастер-узла кластера. По ее истечении проверьте работу usernetes (rootless kuber)
Проверка работы master-узла
На master-узле выполните команду:
# kubectl get daemonsets.apps -A NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE kube-flannel kube-flannel-ds 1 1 1 1 1 <none> 102s kube-system kube-proxy 1 1 1 1 1 kubernetes.io/os=linux 8h
Число READY каждого daemonset должно быть равно числу DESIRED и должно быть равно числу узлов кластера.
# kubectl get nodes -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME <host> Ready control-plane 16m v1.26.3 10.96.0.1 <none> ALT SP Server 11100-01 5.15.105-un-def-alt1 cri-o://1.26.2
Проверьте работу usernetes (rootless kuber)
# kubectl get all -A NAMESPACE NAME READY STATUS RESTARTS AGE kube-system pod/coredns-c7df5cd6c-5pkkm 1/1 Running 0 19m kube-system pod/coredns-c7df5cd6c-cm6vf 1/1 Running 0 19m kube-system pod/etcd-host-212 1/1 Running 0 19m kube-system pod/kube-apiserver-host-212 1/1 Running 0 19m kube-system pod/kube-controller-manager-host-212 1/1 Running 0 19m kube-system pod/kube-proxy-lqf9c 1/1 Running 0 19m kube-system pod/kube-scheduler-host-212 1/1 Running 0 19m NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE default service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 19m kube-system service/kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 19m NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE kube-system daemonset.apps/kube-proxy 1 1 1 1 1 kubernetes.io/os=linux 19m NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE kube-system deployment.apps/coredns 2/2 2 2 19m NAMESPACE NAME DESIRED CURRENT READY AGE kube-system replicaset.apps/coredns-c7df5cd6c 2 2 2 19m
Состояние всех Pod’ов должны быть в 1/1.
Проверьте состояние дерева rootless-процессов:
# pstree
...
├─systemd─┬─(sd-pam)
│ ├─dbus-daemon
│ ├─nsenter.sh───nsenter───_kubelet.sh───kubelet───11*[{kubelet}]
│ └─rootlesskit.sh───rootlesskit─┬─exe─┬─conmon───kube-controller───7*[{kube-controller}]
│ │ ├─conmon───kube-apiserver───8*[{kube-apiserver}]
│ │ ├─conmon───kube-scheduler───7*[{kube-scheduler}]
│ │ ├─conmon───etcd───8*[{etcd}]
│ │ ├─conmon───kube-proxy───4*[{kube-proxy}]
│ │ ├─2*[conmon───coredns───8*[{coredns}]]
│ │ ├─rootlesskit.sh───crio───10*[{crio}]
│ │ └─7*[{exe}]
│ ├─slirp4netns
│ └─8*[{rootlesskit}]
...
Процесс kubelet запускается как сервис в user namespace процесса rootlesskit.
Все остальные процессы kube-controller, kube-apiserver, kube-scheduler, kube-proxy, etcd, coredns запускаются как контейнеры от соответствующих образов в user namespace процесса rootlesskit.
Обеспечение запуска обычных POD’ов на мастер-узле
По умолчанию на master-узле пользовательские Podы не запускаются. Чтобы снять это ограничение наберите команду:
# kubectl taint nodes <host> node-role.kubernetes.io/control-plane:NoSchedule- node/<host> untainted
Инициализация и подключение worker-узла
Установите пакет podsec-k8s:
apt-get install podsec-k8s
Измените переменную PATH:
export PATH=/usr/libexec/podsec/u7s/bin/:$PATH
Подключение worker-узлов
Скопируйте команду подключения worker-узла, полученную на этапе установки начального master-узла. Запустите ее:
kubeadm join xxx.xxx.xxx.xxx:6443 --token ... --discovery-token-ca-cert-hash sha256:...
По умолчанию уровень отладки устанавливается в
0. Если необходимо увеличить уровень отладки укажите перед подкомандойjoinфлаг-v n. Гдеnпринимает значения от0до9-ти.
По окончании скрипт выводит текст:
This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details. Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
Проверка состояния процессов
Проверьте состояние дерева rootless-процессов:
# pstree
...
├─systemd─┬─(sd-pam)
│ ├─dbus-daemon
│ ├─nsenter.sh───nsenter───_kubelet.sh───kubelet───10*[{kubelet}]
│ └─rootlesskit.sh───rootlesskit─┬─exe─┬─conmon───kube-proxy───4*[{kube-proxy}]
│ │ ├─rootlesskit.sh───crio───9*[{crio}]
│ │ └─6*[{exe}]
│ ├─slirp4netns
│ └─8*[{rootlesskit}]
...
Процесс kubelet запускается как сервис в user namespace процесса rootlesskit.
Все остальные процессы kube-proxy, kube-flannel запускаются как контейнеры от соответствующих образов в user namespace процесса rootlesskit.
Проверка готовности master и worker узлов kubernets
Зайдите на master-узел и проверьте подключение worker-узла:
# kubectl get nodes -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME <host1> Ready control-plane 7h54m v1.26.3 10.96.0.1 <none> ALT cri-o://1.26.2 <host2> Ready <none> 8m30s v1.26.3 10.96.0.1 <none> ALT cri-o://1.26.2 ...
Инициализация и подключение дополнительных master-узлов
Установите пакет podsec-k8s:
apt-get install podsec-k8s
Измените переменную PATH:
export PATH=/usr/libexec/podsec/u7s/bin/:$PATH
Подключение master-узлов
Скопируйте команду подключения master-узла, полученную на этапе установки начального master-узла.
Она отличается от команды подключения worker-узлов наличием дополнительных параметров
--control-plane, --certificate-key.
Запустите ее:
kubeadm join xxx.xxx.xxx.xxx:6443 --token ... --discovery-token-ca-cert-hash sha256:... --control-plane --certificate-key ...
По умолчанию уровень отладки устанавливается в
0. Если необходимо увеличить уровень отладки укажите перед подкомандойjoinфлаг-v n. Гдеnпринимает значения от0до9-ти.
По окончании скрипт выводит текст:
This node has joined the cluster and a new control plane instance was created: * Certificate signing request was sent to apiserver and approval was received. * The Kubelet was informed of the new secure connection details. * Control plane label and taint were applied to the new node. * The Kubernetes control plane instances scaled up. * A new etcd member was added to the local/stacked etcd cluster.
Проверка состояния процессов
Проверьте состояние дерева процессов:
# pstree
...
├─systemd─┬─(sd-pam)
│ ├─dbus-daemon
│ ├─kubelet.sh───nsenter_u7s───nsenter───_kubelet.sh───kubelet───11*[{kubelet}]
│ └─rootlesskit.sh───rootlesskit─┬─exe─┬─conmon───kube-controller───4*[{kube-controller}]
│ │ ├─conmon───kube-scheduler───8*[{kube-scheduler}]
│ │ ├─conmon───etcd───9*[{etcd}]
│ │ ├─conmon───kube-proxy───4*[{kube-proxy}]
│ │ ├─conmon───kube-apiserver───8*[{kube-apiserver}]
│ │ ├─rootlesskit.sh───crio───8*[{crio}]
│ │ └─7*[{exe}]
│ ├─slirp4netns
│ └─8*[{rootlesskit}]
Дерево rootless-процессов должно отличаться от дерева процессов основного master-узла
отсутствием контейнеров coredns.
Проверка готовности master и worker узлов kubernets
На одном из master-узлов наберите команду:
# kubectl get nodes -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME <host1> Ready control-plane 7h54m v1.26.3 10.96.0.1 <none> ALT cri-o://1.26.2 <host2> Ready <none> 8m30s v1.26.3 10.96.0.1 <none> ALT cri-o://1.26.2 ... <hostN> Ready control-plane 55m v1.26.3 10.96.122.<N> <none> ALT cri-o://1.26.2 ...
Использование REST-интерефейсов подключенных master-узлов
По умолчанию на подключенных master-узлах в файле /etc/kubernetes/admin.conf
указан адрес API-интерфейса основного master-узла:
apiVersion: v1
clusters:
- cluster:
...
server: https://<master1>:6443
...
Для балансировки нагрузки в файлах конфигурации ~user/.kube/config
есть смысл указать адреса API-интерфейсов дополнительгных master-узла:
apiVersion: v1
clusters:
- cluster:
...
server: https://<masterN>:6443
...
Системный пользователь u7s-admin
Все контейнеры в rootless kubernetes. включая системные работают от имени системного пользователя u7s-admin.
Вы можете для мониторинга работы системы или запуска дополнительного функционала работать в системе от имени этого пользователя.
Для входа в терминальный режим этого пользователя достаточно в пользователе с правами root набрать команду:
# machinectl shell u7s-admin@ /bin/bash
или задав пароль пользователя:
# passwd u7s-admin
зайти в него через ssh.
Для входа в namespace пользователя наберите команду :
$ nsenter_u7s #
В рамках своего namespace пользователь u7s-admin имеет права root, оставаясь в рамках системы
с правам пользователя u7s-admin.
Наличие прав root позволает использовать системные команды,требующих root-привелегий для работы с сетевым, файловым окружением (эти окружения отличаются от системных): ip, iptables, crictl, ...
С помощью команды crictl можно
- посмотреть наличие образов в системном кэше,
- удалить, загрузить образы
- посмотреть состояние контейнеров, pod'ов
- и т.п.
Кроме этого namespace пользователя u7s-admin присутствуют файлы и каталоге созданные в рамках данного
namespace и отсутствующие в основной системе.
Например Вы можете посмотреть логи контейнеров в каталоге /var/log/pods и т.п.
Особенности разворачивания приложений в rootless kubernetes
При использовании сервисов типа NodePort поднятые в рамках кластера порты в диапазоне 30000-32767 остаются в namespace пользователя u7s-admin. Для их проброса наружу необходимо в пользователе u7s-admin запустить команду:
$ nsenter_u7s rootlessctl add-ports 0.0.0.0:<port>:<port>/tcp
Сервисы типа NodePort из за их небольшого диапазона и "нестабильности" портов при переносе решения в другой кластер довольно редко используются. Рекомендуется вместо них использовать сервисы типа ClusterIP c доступом к ним через Ingress-контроллеры.
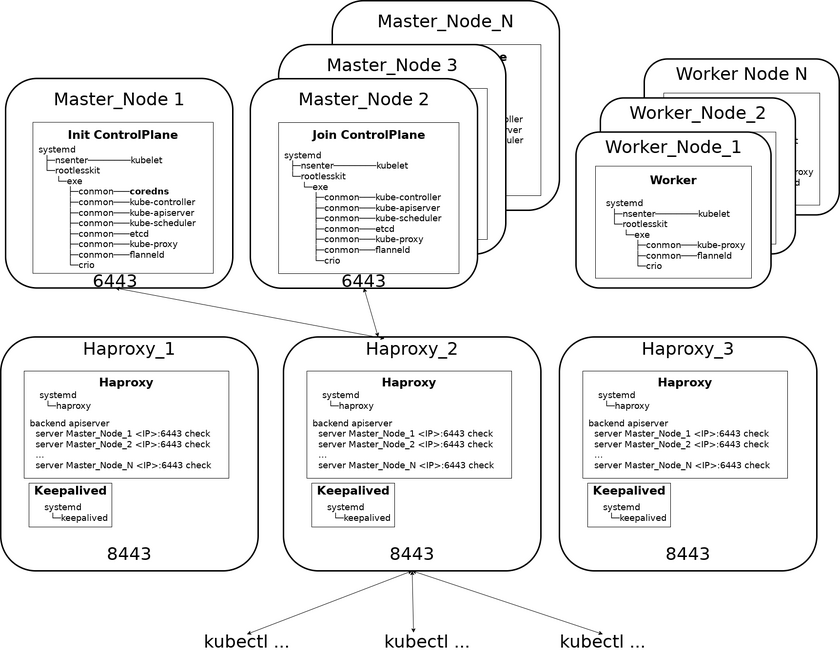
Разворачивание rootless kubernetes кластера с балансировщиком REST-запросов haproxy
Вышеописанный процесс разворачивания обеспечивать только ручную балансировку запросов:

Ручная балансировка запросов к API-интерфейсам master-узлов путем указания у клиентов адресов различных
master-узлов довольно неудобна, так как не обеспечивает равномерного распределения запросов по узлам кластера и не обеспечивает автоматической отказоустойчивости при выходе из строя master-узлов.
Решает данную проблему установка балансировщика нагрузки haproxy.

Перевод кластера в режим балансировки запросов через haproxy возможен.
Подробности описаны в статье How to convert a Kubernetes non-HA control plane into an HA control plane?, но данная процедура не гарантирует корректный перевод на всех версиях kubernetes и ее не рекомендуют применять на production кластерах.
Так что наиболее надежным способом создания кластера с балансировкой запросов является создание нового кластера.
Настройка балансировщика REST-запросов haproxy
Балансировщик REST-запросов haproxy можно устанавливать как на отдельный сервер, так на один из серверов кластера.

Если балансировщик устанавливается на
rootlessсервер кластера, то для балансировщика необходимо выделить отдельный IP-адрес. Если на этом же сервере функционируют локальный регистратор (registry.local) и сервер подписей (sigstore.local), то IP-адрес балансировщика может совпадать c IP-адресами этих сервисов.
Если планируется создание отказоустойчивого решения на основе нескольких серверов
haproxy, то для них кроме собственногоIP-адресанеобходимо будет для всех серверовhaproxyвыделить один общийIP-адрес, который будет иметьmaster-балансировщик.
Полная настройка отказоустойчивого кластера haproxy из 3-х узлов описана в документе ALT Container OS подветка K8S. Создание HA кластера.
Здесь же мы рассмотрим создание и настройка с одним сервером haproxy с балансировкой запросов на master-узлы.
Установите пакет haproxy:
# apt-get install haproxy
Отредактируйте конфигурационный файл /etc/haproxy/haproxy.cfg:
- добавьте в него описание
frontend’amain, принимающего запросы по порту8443:frontend main bind *:8443 mode tcp option tcplog default_backend apiserver
- добавьте описание
backend’аapiserver:backend apiserver option httpchk GET /healthz http-check expect status 200 mode tcp option ssl-hello-chk balance roundrobin server master01 <IP_или_DNS_начального_мастер_узла>:6443 check - запустите
haproxy:
# systemctl enable haproxy # systemctl start haproxy
Инициализация master-узла
Инициализация мастер-узла при работа с балансировщиков haproxy
При установке начального master-узла необходимо параметром control-plane-endpoint указать URL балансировщика haproxy:
# kubeadm init --apiserver-advertise-address 192.168.122.80 --control-plane-endpoint <IP_адрес_haproxy>:8443
При запуске в параметре --apiserver-advertise-address укажите IP-адрес API-интерфейса kube-apiserver.
IP-адреса в параметрах --apiserver-advertise-address и --control-plane-endpoint должны отличаться. Если Вы развернули haproxy на том же мастер-узле, поднимите на сетевом нтерфейсе дополнительный IP-адрес и укажите его в параметре --control-plane-endpoint.
В результате инициализации kubeadm выведет команды подключения дополнительных control-plane и worker узлов:
...
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join <IP_адрес_haproxy>:8443 --token ... \
--discovery-token-ca-cert-hash sha256:... \
--control-plane --certificate-key ...
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join <IP_адрес_haproxy>:8443 --token ... \
--discovery-token-ca-cert-hash sha256:...
...
Обратите внимание - в командах присоединения узлов указывается не URL созданного начального master-узла (<IP_или_DNS_начального_мастер_узла>:6443), а URL haproxy.
В сформированных файлах конфигурации /etc/kubernetes/admin.conf, ~/.kube/config также указывается URL haproxy:
apiVersion: v1
clusters:
- cluster:
...
server: https://<IP_адрес_haproxy>:8443
То есть вся работа с кластеров в дальнейшем идет через балансировщик запросов haproxy.
Для перевода узла в состояние Ready, запуска coredns Pod’ов запустите flannel
Запуск сетевого маршрутизатора для контейнеров kube-flannel
На master-узле под пользоваталем root выполните команду:
# kubectl apply -f /etc/kubernetes/manifests/kube-flannel.yml Connected to the local host. Press ^] three times within 1s to exit session. [INFO] Entering RootlessKit namespaces: OK namespace/kube-flannel created clusterrole.rbac.authorization.k8s.io/flannel created clusterrolebinding.rbac.authorization.k8s.io/flannel created serviceaccount/flannel created configmap/kube-flannel-cfg created daemonset.apps/kube-flannel-ds created Connection to the local host terminated.
После завершения скрипта в течении минуты настраиваются сервисы мастер-узла кластера. По ее истечении проверьте работу usernetes (rootless kuber)
Подключение дополнительных master-узлов
nj ghbxb
Получении строки подключения Control-plane узла к кластеру
В определенных случаях `kubeadm init` генерирует только строку подключения `worker` узлов. Или срок действия сертификата для подключения истек.
В этом случае есть смысл перегенерировать сертификат и строку подключения `control-plane` и `worker` узлов к кластеру.
Установка тропы PATH поиска исполняемых команд
Измените переменную PATH:
export PATH=/usr/libexec/podsec/u7s/bin/:$PATH
Подключение master (control plane) узла
Скопируйте строку подключения control-plane узла и вызовите ее:
# kubeadm join <IP_адрес_haproxy>:8443 --token ... \
--discovery-token-ca-cert-hash sha256:... \
--control-plane --certificate-key ...
В результате работы команда kubeadm выведет строки:
This node has joined the cluster and a new control plane instance was created: * Certificate signing request was sent to apiserver and approval was received. * The Kubelet was informed of the new secure connection details. * Control plane label and taint were applied to the new node. * The Kubernetes control plane instances scaled up. * A new etcd member was added to the local/stacked etcd cluster. ... Run 'kubectl get nodes' to see this node join the cluster.
Наберите на вновь созданном (или начальном)control-plane узле команду:
# kubectl get nodes NAME STATUS ROLES AGE VERSION <host1> Ready control-plane 4m31s v1.26.3 <host2> Ready control-plane 26s v1.26.3
Обратите внимание, что роль (ROLES) обоих узлов - control-plane.
Наберите команду:
# kubectl get all -A NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES kube-flannel pod/kube-flannel-ds-2mhqg 1/1 Running 0 153m 10.96.0.1 <host1> <none> <none> kube-flannel pod/kube-flannel-ds-95ht2 1/1 Running 0 153m 10.96.122.68 <host2> <none> <none> ... kube-system pod/etcd-<host1> 1/1 Running 0 174m 10.96.0.1 <host1> <none> <none> kube-system pod/etcd-<host2> 1/1 Running 0 170m 10.96.122.68 <host2> <none> <none> kube-system pod/kube-apiserver-<host1> 1/1 Running 0 174m 10.96.0.1 <host1> <none> <none> kube-system pod/kube-apiserver-<host2> 1/1 Running 0 170m 10.96.122.68 <host2> <none> <none> kube-system pod/kube-controller-manager-<host1> 1/1 Running 1 (170m ago) 174m 10.96.0.1 <host1> <none> <none> kube-system pod/kube-controller-manager-<host2> 1/1 Running 0 170m 10.96.122.68 <host2> <none> <none> kube-system pod/kube-proxy-9nbxz 1/1 Running 0 174m 10.96.0.1 <host1> <none> <none> kube-system pod/kube-proxy-bnmd7 1/1 Running 0 170m 10.96.122.68 <host2> <none> <none> kube-system pod/kube-scheduler-<host1> 1/1 Running 1 (170m ago) 174m 10.96.0.1 <host1> <none> <none> kube-system pod/kube-scheduler-<host2> 1/1 Running 0 170m 10.96.122.68 <host2> <none> <none> ... NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE CONTAINERS IMAGES SELECTOR kube-flannel daemonset.apps/kube-flannel-ds 2 2 2 3 3 <none> 153m kube-flannel registry.local/k8s-c10f1/flannel:v0.19.2 app=flannel kube-system daemonset.apps/kube-proxy 2 2 2 2 2 kubernetes.io/os=linux 174m kube-proxy registry.local/k8s-c10f1/kube-proxy:v1.26.3 k8s-app=kube-proxy ...
Убедитесь, что сервисы pod/etcd, kube-apiserver, kube-controller-manager, kube-scheduler, kube-proxy, kube-flannel запустились на обоих control-plane узлах.
Добавление master-узла в балансироващик haproxy
Для балансировки запросов по двум серверам добавьте URL подключенного control-plane узла в файл конфигурации /etc/haproxy/haproxy.cfg:
backend apiserver
option httpchk GET /healthz
http-check expect status 200
mode tcp
option ssl-hello-chk
balance roundrobin
server master01 <IP_или_DNS_начального_мастер_узла>:6443 check
server master02 <IP_или_DNS_подключенного_мастер_узла>:6443 check
и перезапустите haproxy:
# systemctl restart haproxy
Логи обращений и балансировку запросов между узлами можно посмотреть командой:
# tail -f /var/log/haproxy.log
Подключение worker-узлов
Подключение дополнительных worker-узлов происходит аналогично описанному выше в главе Инициализация и подключение worker-узла.
Настройка отказоустойчивого кластера серверов haproxy, keepalived
Масштабирование haproxy, установка пакетов
Если необходимо создать отказоустойчивое решение допускающее выход haproxy-севрера из строя
установите haproxy на несколько серверов. Файлы конфигурации haproxy<.code> на всех сервервх должны быть идентичны.
Для контроля доступности haproxy и переназначений виртуального адреса дополнительно установите на каждом сервис keepalived:
# apt-get install haproxy keepalived
Конфигурирование keepalived

Создайте файл конфигурации 'keepalived' /etc/keepalived/keepalived.conf:
! /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id LVS_K8S
}
vrrp_script check_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 3
weight -2
fall 10
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface br0
virtual_router_id 51
priority 101
authentication {
auth_type PASS
auth_pass 42
}
virtual_ipaddress {
10.150.0.160
}
track_script {
check_apiserver
}
}
На одном из узлов установите параметр state в значение MASTER и параметр priority в значение 101.
На остальных параметр state в значение BACKUP и параметр priority в значение 100.
Скрипт /etc/keepalived/check_apiserver.sh проверяет доступность балансировщика haproxy:
#!/bin/sh
errorExit() {
echo "*** $*" 1>&2
exit 1
}
APISERVER_DEST_PORT=8443
APISERVER_VIP=10.150.0.160
curl --silent --max-time 2 --insecure https://localhost:${APISERVER_DEST_PORT}/ -o /dev/null || errorExit "Error GET https://localhost:${APISERVER_DEST_PORT}/"
if ip addr | grep -q ${APISERVER_VIP}; then
curl --silent --max-time 2 --insecure https://${APISERVER_VIP}:${APISERVER_DEST_PORT}/ -o /dev/null || errorExit "Error GET https://${APISERVER_VIP}:${APISERVER_DEST_PORT}/"
fi
Параметр APISERVER_DEST_PORT задает порт балансировщиков haproxy, параметр APISERVER_VIP виртуальный адрес,
через который будут взаимодействовать master (control plane) узлы кластера k8s.
Скрипт проверяет работоспособность haproxy на локальной машине.
Подробности см. на [[1]]
А если в настоящее время виртуальный адрес принадлежит текущему узлу, то и работоспособность haproxy через виртуальный адрес.
Добавьте флаг на выполнение скрипта:
chmod a+x /etc/keepalived/check_apiserver.sh
При работающем балансировщике и хотя бы одному доступному порту 6443 на master-узлах скрипт
должен завершаться с кодом 0.
Подробности см. на Keepalived
Установка и настройка ingress-контролера
Ingress-контроллер обеспечивает переадресацию http(s) запросов по указанным шаблонам на внутренние сервисы kubernetes-кластера.
Для bare-metal решений и решений на основе виртуальных машин наиболее приемлимым является
ingress-nginx контроллер.
При применении Ingress-контроллера нет необходимости создавать Nodeport-порты и пробрасывать их из namespace пользователя u7s-admin. Ingress-контроллер переадресует http{s) запрос через сервис непосредственно на порты Pod'ов входящих в реплики deployment.
Установка и настройка ingress-nginx-контролера в кластере
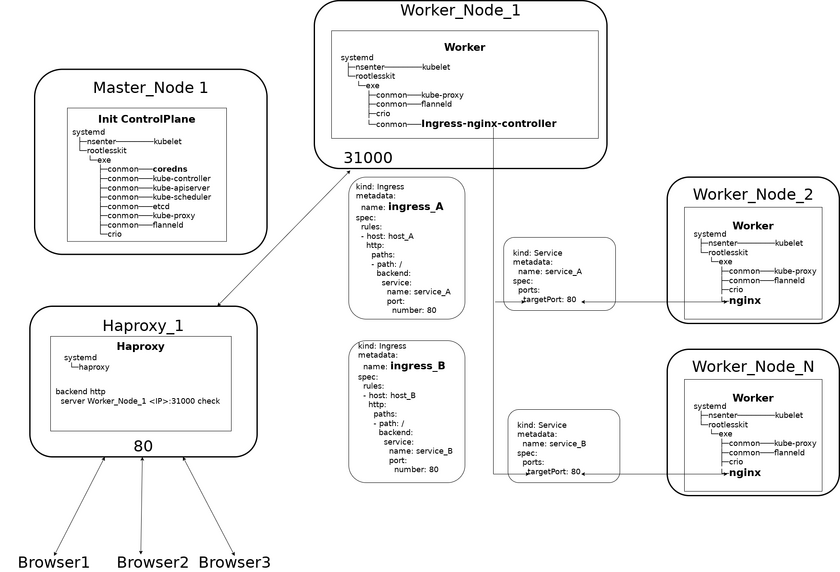

Для установки Ingress-контроллера скопируйте его YAML-манифест:
curl https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.8.0/deploy/static/provider/baremetal/deploy.yaml -o ingress-nginx-deploy.yaml
Выберите свободный порт в диапазона 30000 - 32767 (например 31000) и добавьте его в элемент
spec.ports.appProtocol==http
Yaml-описании kind==Service:
...
---
kind: Service
spec:
ports:
- appProtocol: http
...
nodePort: 31000
...
Если в Вашем решении используется ТОЛЬКО локальный регистратор registry.local
- создайте алиасы образам nginx:
podman tag registry.k8s.io/ingress-nginx/controller:v1.8.0@sha256:744ae2afd433a395eeb13dc03d3313facba92e96ad71d9feaafc85925493fee3 registry.local/ingress-nginx/controller:v1.8.0
podman tag registry.k8s.io/ingress-nginx/kube-webhook-certgen:v20230407@sha256:543c40fd093964bc9ab509d3e791f9989963021f1e9e4c9c7b6700b02bfb227b registry.local/ingress-nginx/kube-webhook-certgen:v20230407
и поместите их в локальный регистратор:
podman push --tls-verify=false --sign-by='<EMAIL>' registry.local/ingress-nginx/controller
podman push --tls-verify=false --sign-by='<EMAIL>' registry.local/ingress-nginx/kube-webhook-certgen
- исправьте имена образов в скачанном нанифесте на имена образов в локальном регистраторе.
Запустите Ingress-nginx-контролер:
kubectl apply -f ingress-nginx-deploy.yaml
На одном или нескольких kubernet-узлах (эти узла в дальнейшем нужно прописать в файле конфигурации балансировщика haproxy) пробросьте порт nginx-контроллера (31000) из namespace пользователя u7s-admin в сеть kubernetes:
nsenter_u7s rootlessctl add-ports 0.0.0.0:31000:31000/tcp
Настройка Ingress-правил
Kubernetes поддерживает манифесты типа Ingress (kind: Ingress) описывающие правила переадресации запросов URL http-запррса на внутренние порты сервисов (kind: Service) kubernetes. Сервисы в свою очередь перенаправляют запросы на реплики Pod'ов, входящих в данный сервис.
Общий вид Ingress-манифеста:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: <ingress_имя>
spec:
ingressClassName: nginx
rules:
- host: <домен_1>
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: <имя_сервиса_1>
port:
number: 80
- path: /<тропа_1>
pathType: Prefix
backend:
service:
name: <имя_сервиса_2>
port:
number: 80
- host: <домен_2>
...
Где:
host: <домен_1>, <домен_2>, ... - домены WEB-серверов на которых приходит запрос;path:/>, path:/<тропа_1> - тропы (префиксы запросов после домена)pathType: Prefix - тип троп: Prefix или Exact;service: - имя сервиса на который перенаправляется запрос, если полученный запрос соответсвует правилу;port - номер порта на который перенаправляется запрос.
Если запросу соответствует несколько правил, выбирается правило с наиболее длинным префиксом.
Подробности смотри в Kubernetes: Ingress
Настройка haproxy и DNS
Добавьте в файлы конфигурации haproxy /etc/haproxy/haproxy.conf переадресацию запросов на порт 80 (http) по IP-адресу балансировщика haproxy на IP-адреса kubernet-узлов на которых выбранный порт nginx-контроллера (31000) проброшен из namespace пользователя u7s-admin в сеть kubernetes:
frontend http
bind *:80
mode tcp
option tcplog
default_backend http
backend http
mode tcp
balance roundrobin
server <server1> <ip1>:31000 check
server <server2> <ip2>:31000 check
Заведите DNS-запись связывающую DNS-имя http-сервиса с IP-адресам haproxy-сервера.
Выбор исходного регистратора kubernetes-образов
Во время инициализации master-узла кластера (kubeadm init) или во время подключения узла к кластеру (kubeadm join) команда kubeadm может загружать образы с различных регистраторов образов и с различными префиксами.
Выбор регистратора и префикса образов определяет переменная среды U7S_REGISTRY.
Если переменная не задана регистратор префикс определяется автоматически на основе конфигурационных файлов /etc/os-release и /etc/hosts.
Переменная среды U7S_REGISTRY может принимать следующие основные значения:
- пустое значение;
registry.altlinux.org/k8s-c10f1;registry.altlinux.org/k8s-p10;registry.local/k8s-c10f1;registry.local/k8s-p10.
Native kubernetes регистратор
export U7S_REGISTRY=
Если переменная U7S_REGISTRY установлена в пустое значение образы загружаются со стандартного регистратора образов kubernetes.
Регистратор altlinux
С регистратора altlinux устанавливаются образы для которых не требуются ограничения политики доступа для различных категория пользователей:
export U7S_REGISTRY=registry.altlinux.org/k8s-c10f1 - образы для сертфицированного дистрибутива c10;export U7S_REGISTRY=registry.altlinux.org/k8s-p10 - образы для несертфицированного дистрибутива p10.
podsec - Локальный регистратор
Локальный регистратор образов registry.local может обеспечивать:
- разворачивание кластера без доступа в Интернет;
- ускоренное разворачивание как кластера, так и проектов, разворачиваемых в его рамках, так как образы необходимые для запуска
Pod'ов загружаются по локальной сети;
- высокий уровень защищенности системы путем установки политик разрешающих загрузку только подписанных образов и только с локального регистратора
registry.local.
Пакет podsec обеспечивает:
- Установку на рабочих местах клиентов и узлах
kubernetes политик доступа к образом для различных категория пользователей (скрипт podsec-create-policy).
- Разворачивание на одном узлов локального регистратора образов и сервера подписей образов (скрипт
podsec-create-services).
- Загрузку с регистратора
registry.altlinux.org образов необходимых для разворачивания kubernetes и формирования максимально сжатого (<200Mb) архива. (скрипты podsec-k8s-save-oci, podsec-save-oci)
- разворачивание образов из архива, их подпись размещение на локальном регистраторе (скрипт
podsec-load-sign-oci).
В зависимости от дистрибутива скрипт podsec-k8s-save-oci формирует архив образов:
registry.local/k8s-c10f1 - архив образов для сертифицированного дистрибутива c10 на основе набора образов с регистратора registry.altlinux.org с префиксом k8s-c10f1;registry.local/k8s-p10 - архив образов для несертифицированного дистрибутива p10 на основе набора образов с регистратора registry.altlinux.org с префиксом k8s-p10;
Локальный регистратор registry.local может также хранить подписанные образы и запускаемых в рамках кластера проектов. Необходимо только, чтобы каждый образ в рамках локального регистратор registry.local имел префикс. Образы типа registry.local/<имя_образа> не допускаются, так как для них трудно определить "подписанта" образа.
podsec-create-policy - настройка политики доступа к образам различным категориям пользователей
Формат:
podsec-create-policy <ip-адрес_регистратора_и_сервера_подписей>
Описание:
Скрипт podsec-create-policy формирует в файлах /etc/containers/policy.json,
/etc/containers/registries.d/default.yaml максимально защищенную политику доступа к образам - по умолчанию допускается доступ только к подписанным образам локального регистратора registry.local.
Данная политика распространяется как на пользователей имеющих права суперпользователя, так и на пользователей группы podsec, создаваемые podsec-скриптом podsec-create-podmanusers.
Пользователи группы podsec-dev, создаваемые podsec-скриптом podsec-create-imagemakeruser имеют неограниченные права на доступ, формирования образов, их подпись и помещение на локальный регистратор registry.local.
В разворачиваниях kubernetes не требующих таких жестких ограничений в политике доступа и работы с образами политики могут быть смягчены путем модифицирования cистемных файлов политик /etc/containers/policy.json, /etc/containers/registries.d/default.yaml или файлов установки политик пользователей ~/.config/containers/policy.json, ~/.config/containers/registries.d/default.yaml.
podsec-create-services - разворачивание локального регистратора образов и сервера подписей образов
Скрипт podsec-create-services обеспечивает разворачивание локального регистратора образов и сервера подписей образов.
Поддержка электронной подписи образов
Для kubernetes-образов, хранящихся в архиве образов распаковку образов, их подпись и размещение на локальном регистраторе registry.local обеспечивает скрипт podsec-load-sign-oci запускаемый пользователем группы podsec-dev.
Для других образов пользователь группы podsec-dev должен создать образ в домене локального регистратора registry.local/</prefix>/ и поместить его в регистратор командой:
podman push --tls-verify=false --sign-by="<email-подписанта" <образ>
Образ в домене registry.local/</prefix>/ может быть получен:
- присваивании алиаса стороннему образу:
podman tag <сторонний_образ> registry.local/</prefix>/<локальный_образ>
- сборки образов через
Dockerfile.
podman build -t registry.local/</prefix>/<локальный_образ> ...
Автоматический выбор регистратора образов
Если переменная U7S_REGISTRY не установлена, ее значения вычисляется автоматически по следующему алгоритму:
- Если файл
/etc/hosts содержит описание хоста registry.local префикс переменной U7S_REGISTRY принимает значение registry.local/, иначе registry.altlinux.org/.
- Если переменная
CPE_NAME файла /etc/os-release содержит значение spserver суффикс переменной U7S_REGISTRY принимает значение k8s-c10f1, иначе k8s-p10.
podsec-k8s-rbac - Поддержка управление доступом на основе ролей (RBAC)
В пакет podsec-k8s-rbac входит набор скриптов для работы с RBAC - Role Based Access Control:
podsec-k8s-rbac-create-user - создание RBAC-пользователя;podsec-k8s-rbac-create-kubeconfig - создание ключей, сертификатов и файла конфигурации RBAC-пользователя;podsec-k8s-rbac-create-remoteplace - создание удаленного рабочего места;podsec-k8s-rbac-bindrole - привязывание пользователя к кластерной или обычной роли;podsec-k8s-rbac-get-userroles - получить список кластерные и обычных ролей пользователя;podsec-k8s-rbac-unbindrole - отвязывание пользователя от кластерной или обычной роли.
podsec-k8s-rbac-create-user - создание RBAC-пользователя
Формат:
podsec-k8s-rbac-create-user имя_пользователя
Описание:
Скрипт:
- создает RBAC пользователя
- создает в домашнем директории каталог .kube
- устанавливаются соответствующие права доступа к каталогам.
podsec-k8s-rbac-create-kubeconfig - создание ключей, сертификатов и файла конфигурации RBAC-пользователя
Формат:
podsec-k8s-rbac-create-kubeconfig имя_пользователя[@<имя_удаленного_пользователя>] [группа ...]
Описание:
Скрипт должен вызываться администратором безопасности средства контейнеризации.
Для rootless решения имя удаленного пользователя принимается u7s-admin.
Для rootfull решения необходимо после символа @ указать имя удаленного пользователя.
Скрипт в каталоге ~имя_пользователя/.kube производит:
- Создании личного (private) ключа пользователя (файл
имя_пользователя.key).
- Создание запроса на подпись сертификата (CSR) (файл
имя_пользователя.key).
- Запись
запроса на подпись сертификата CSR в кластер.
- Подтверждение
запроса на подпись сертификата (CSR).
- Создание
сертификата (файл имя_пользователя.crt).
- Проверку корректности сертификата
- Формирование файла конфигурации пользователя (файл
config)
- Добавление контекста созданного пользователя
podsec-k8s-rbac-create-remoteplace - создание удаленного рабочего места
Формат:
podsec-k8s-rbac-create-remoteplace ip-адрес
Описание:
Скрипт производит настройку удаленного рабочего места пользователя путем копирования его конфигурационного файла.
podsec-k8s-rbac-bindrole - привязывание пользователя к кластерной или обычной роли
Формат:
podsec-k8s-rbac-bindrole имя_пользователя role|role=clusterrole|clusterrole роль имя_связки_роли [namespace]
Описание:
Скрипт производит привязку пользователя к обычной или кластерной роли используя имя_связки_роли.
Параметры:
- имя_пользователя должно быть создано командой podsec-k8s-rbac-create-user и сконфигурировано на доступ к кластеру командой podsec-k8s-rbac-create-kubeconfig;
- тип роли может принимать следующие значения:
* role - пользователь привязывется к обычной роли с именем <роль> (параметр namespace в этом случае обязателен);
* role=clusterrole - пользователь привязывется к обычной роли используя кластерную роль с именем <роль> (параметр namespace в этом случае обязателен);
* clusterrole - пользователь привязывется к кластерной роли используя кластерную роль с именем <роль> (параметр namespace в этом случае должен отсутствовать).
- роль - имя обычной или кластерной роли в зависимости от предыдущего параметра;
- имя_связки_роли - имя объекта класса rolebindings или clusterrolebindings в зависимости от параметра тип роли. В рамках этого объекта к кластерной или обычной роли могут быть привязаны несколько пользователей.
- namespace - имя namespace для обычной роли.
podsec-k8s-rbac-get-userroles - получить список кластерные и обычных ролей пользователя
Формат:
podsec-k8s-rbac-get-userroles имя_пользователя [showRules]
Описание:
Скрипт формирует список кластерные и обычных ролей которые связаны с пользователем. При указании флага showRules, для каждой роли указывается список правил ("rules:[...]"), которые принадлежат каждой роли пользователя.
Результат возвращается в виде json-строки формата:
{
"": {
"clusterRoles": [...],
"roles": {
"allNamespaces": [...],
"namespaces": [
{
"": [...],
...
}
}
}
}
Где [...] - массив объектов типа:
{
"bindRoleName": "",
"bindedRoleType": "ClusterRole|Role",
"bindedRoleName": "",
"unbindCmd": "podsec-k8s-rbac-unbindrole ..."
}
podsec-k8s-rbac-unbindrole - отвязывание пользователя от кластерной или обычной роли
Формат:
podsec-k8s-rbac-unbindrole имя_пользователя role|clusterrole роль имя_связки_роли [namespace]
Описание:
Скрипт производит отвязку роли от кластерной или обычной роли, созданной командой podsec-k8s-rbac-bindrole. Полный текст команды можно получить в выводе команды podsec-k8s-rbac-get-userroles в поле unbindCmd. Если в указанном имя_связки_роли объекте класса rolebindings или clusterrolebindings еще остаются пользователи - объект модифицируется. Если список становится пуст - объект удаляется.
Параметры:
имя_пользователя должно быть создано командой podsec-k8s-rbac-create-user и сконфигурировано на доступ к кластеру командой podsec-k8s-rbac-create-kubeconfig;- тип роли может принимать следующие значения:
* role - пользователь привязывается к обычной роли с именем <роль> (параметр namespace в этом случае обязателен);
* clusterrole - пользователь привязывается к кластерной роли используя кластерную роль с именем <роль> (параметр namespace в этом случае должен отсутствовать).
роль - имя обычной или кластерной роли в зависимости от предыдущего параметра;имя_связки_роли - имя объекта класса rolebindings или clusterrolebindings в зависимости от параметра тип роли. В рамках этого объекта к кластерной или обычной роли могут быть привязаны несколько пользователей.namespace - имя namespace для обычной роли.
podsec-inotify - Мониторинг безопасности системы
В пакет podsec-inotify входит набор скриптов для мониторинга безопасности системы:
- podsec-inotify-check-policy - проверка настроек политики контейнеризации на узле;
- podsec-inotify-check-containers - проверка наличия изменений файлов в директориях rootless контейнерах;
- podsec-inotify-check-images - проверка образов на предмет их соответствия настройки политикам контейнеризации на узле;
- podsec-inotify-check-kubeapi - мониторинг аудита API-интерфейса kube-apiserver control-plane узла;
- podsec-inotify-check-vuln - мониторинг docker-образов узла сканером безопасности trivy.
podsec-inotify-check-policy - проверка настроек политики контейнеризации на узле
Формат:
podsec-inotify-check-policy [-v[vv]] [-a интервал] [-f интервал] -c интервал -h интервал [-m интервал] х-w интервалъ [-l интервал] [-d интервал]
Описание:
Плугин проверяет настройки политики контейнеризации на узле.
Проверка идет по следующим параметрам:
- файл
policy.json установки транспортов и политик доступа к регистраторам:
Параметр контроля пользователей
Вес метрики
имеющих defaultPolicy != reject, но не входящих в группу podman_dev
102
не имеющих не имеющих registry.local в списке регистраторов для которых проверяется наличие электронной подписи образов
103
имеющих в политике регистраторы для которых не проверяется наличие электронной подписи образов
104
имеющих в списке поддерживаемых транспорты отличные от docker (транспорт получения образов с регистратора)
105
- файлы привязки регистраторов к серверам хранящим электронные подписи (файл привязки о умолчанию
default.yaml и файлы привязки регистраторов *.yaml каталога registries.d). Наличие (число) пользователей:
Параметр контроля пользователей
Вес метрики
не использующих хранилище подписей http://sigstore.local:81/sigstore/ как хранилище подписей по умолчанию
106
- контроль групп пользователей
- наличие пользователей имеющих образы, но не входящих в группу
podman:
Параметр контроля пользователей
Вес метрики
наличие пользователей имеющих образы, но не входящих в группу podman
101
- наличие пользователей группы
podman (за исключением входящих в группу podman_dev):
Параметр контроля пользователей
Вес метрики
входящих в группу wheel
101
имеющих каталог .config/containers/ открытым на запись и изменения
90 * доля_нарушителей
не имеющих файла конфигурации .config/containers/storage.conf
90 * доля_нарушителей
доля_нарушителей считается как: число_нарушителей / число_пользователей_группы_podman
Все веса метрик суммируются и формируется итоговая метрика.
podsec-inotify-check-containers - проверка наличия изменений файлов в директориях rootless контейнерах
Формат:
podsec-inotify-check-containers
Описание:
Скрипт:
- создаёт список директорий
rootless контейнеров, существующих в системе,
- запускает проверку на добавление,удаление, и изменение файлов в директориях контейнеров,
- отсылает уведомление об изменении в системный лог.
podsec-inotify-check-images - проверка образов на предмет их соответствия настройки политикам контейнеризации на узле
Формат:
podsec-inotify-check-images [-v[vv]] [-a интервал] [-f интервал] -c интервал -h интервал [-m интервал] х-w интервалъ [-l интервал] [-d интервал]
Описание:
Плугин проверяет образы на предмет их соответствия настройки политикам контейнеризации на узле. Проверка идет по следующим параметрам:
Параметр контроля пользователей
Вес метрики
наличие в политике пользователя регистраторов не поддерживающие электронную подпись
101
наличие в кэше образов неподписанных образов
101
наличие в кэше образов вне поддерживаемых политик
101
Все веса метрик суммируются и формируется итоговая метрика.
podsec-inotify-check-kubeapi - мониторинг аудита API-интерфейса kube-apiserver control-plane узла
Формат:
podsec-inotify-check-kubeapi [-d]
Описание:
Скрипт производит мониторинг файла /etc/kubernetes/audit/audit.log аудита API-интерфейса kube-apiserver.
Политика аудита располагается в файле /etc/kubernetes/audit/policy.yaml:
apiVersion: audit.k8s.io/v1
kind: Policy
omitManagedFields: true
rules:
# do not log requests to the following
- level: None
nonResourceURLs:
- "/healthz*"
- "/logs"
- "/metrics"
- "/swagger*"
- "/version"
- "/readyz"
- "/livez"
- level: None
users:
- system:kube-scheduler
- system:kube-proxy
- system:apiserver
- system:kube-controller-manager
- system:serviceaccount:gatekeeper-system:gatekeeper-admin
- level: None
userGroups:
- system:nodes
- system:serviceaccounts
- system:masters
# limit level to Metadata so token is not included in the spec/status
- level: Metadata
omitStages:
- RequestReceived
resources:
- group: authentication.k8s.io
resources:
- tokenreviews
# extended audit of auth delegation
- level: RequestResponse
omitStages:
- RequestReceived
resources:
- group: authorization.k8s.io
resources:
- subjectaccessreviews
# log changes to pods at RequestResponse level
- level: RequestResponse
omitStages:
- RequestReceived
resources:
- group: "" # core API group; add third-party API services and your API services if needed
resources: ["pods"]
verbs: ["create", "patch", "update", "delete"]
# log everything else at Metadata level
- level: Metadata
omitStages:
- RequestReceived
Текущие настройки производят логирование всех обращений "несистемных" пользователей (в том числе анонимных) к ресурсам kubernetes.
Скрипт производит выборку всех обращений, в ответ на которые был сформирован код более 400 - запрет доступа.
Все эти факты записываются в системный журнал и накапливаются в файле логов /var/lib/podsec/u7s/log/kubeapi/forbidden.log, который периодически передается через посту системному адмиристратору.
Параметры:
-d - скирпт запускается в режиме демона, производящего онлайн мониторинг файла /etc/kubernetes/audit/audit.log и записывающего факты запросов с запретом доступа в системный журнал и файл логов /var/lib/podsec/u7s/log/kubeapi/forbidden.log.
- при запуске без параметров скрипт посылает файл логов
/var/lib/podsec/u7s/log/kubeapi/forbidden.log почтой системному администратору (пользователь root) и обнуляет файл логов.
В состав пакета кроме этого скрипта входят:
файл описания сервиса/lib/systemd/system/podsec-inotify-check-kubeapi.service
# systemctl enable podsec-inotify-check-kubeapi.service # systemctl start podsec-inotify-check-kubeapi.service
- файл для cron /etc/podsec/crontabs/podsec-inotify-check-kubeapi. Файл содержит единственную строку с описанием режима запуска скрипта podsec-inotify-check-kubeapi для передачи почты системному администратору.
Скрипт запускается один раз в 10 минут. Во время установки пакета строка файла (в случае ее отсутствия) дописыватся в crontab-файл /var/spool/cron/root пользователя root. Если необходимо изменить режим запуска скрипта или выключить его это можно сделать командой редактирования crontab-файла:
# crontab -e
podsec-inotify-check-vuln - мониторинг docker-образов узла сканером безопасности trivy
Формат:
podsec-inotify-check-vuln
Описание:
Для корректной работы скрипта необходимо запустить сервис podsec-inotify-server-trivy:
systemctl enable --now podsec-inotify-server-trivy
Скрипт производит мониторинг docker-образов узла сканером безопасности trivy:
- Если скрипт запускается от имени пользователя
rootскрипт:
- проверяет сканером
trivyrootfullобразы; - для всех пользователей каталога
/home/проверяется наличиеrootless-образов. При их наличии проверяет сканеромtrivyэти образы.
- Если скрипт запускается от имени обычного пользователя проверяется наличие
rootless-образов. При их наличии проверяет сканеромtrivyэти образы.
Результат анализа посылается в системный лог.
Если при анализе образа число обнаруженных угроз уровня HIGH больше 0, результат посылается почтой системному администратору (root).
Параметры:
Отсутствуют.
В состав пакета кроме этого скрипта входит файл для cron /etc/podsec/crontabs/podsec-inotify-check-vuln. Файл содержит единственную строку с описанием режима запуска скрипта podsec-inotify-check-vuln.
Во время установки пакета строка файла (в случае ее отсутствия) дописыватся в crontab-файл /var/spool/cron/root пользователя root.
Если необходимо изменить режим запуска скрипта или выключить его это можно сделать командой редактирования crontab-файла:
# crontab -e